Solution Concept: GitLab-CI Data Pipelines
Project News
Solution concept for Data Deployment and Data Test Pipelines and implementation based on GitLab-CI
Problem Description
What does ‘Data Deployment’ mean?
In a microservice landscape, data and software can be developed separately and only at runtime in one environment (stage) they are “linked” together. Such a separation is often predetermined by the organizational structure: different departments and teams are responsible for software development and data management. A CI/CD approach then inevitably also affects data management and requires that data is also deployable accordingly to the different stages, just like software. In such a context, a microservice consists of software and data that are developed independently of one another. Before going live, however, the microservice(s) must be extensively tested “as a whole” - i.e. software and data.
What does ‘Data Test’ mean?
In contrast to software testing, data testing focuses on the data. The software (e.g. a microservice) has already been sufficiently tested (through unit tests, automated integration tests, static code analysis, etc.). In the data test, a software artifact with the associated data is automatically tested. Depending on the objective, several so-called Quality Gates can be defined.
What is a ‘Data Depoyment Pipeline’?
A data deployment pipeline orchestrates the deployment and testing of software and data in different stages and defines several quality gates (the need for protection of the data plays an important role) up to the provision in production: the already built software (through a Software-Build-Pipeline), e.g. in the form of Docker Container, is “linked” to a new data version - for example via configuration, then tested and finally put into production.
Solution
Main Features of the Pipeline:
- Automatic rollback of all dependent microservices (dependency in terms of “shared data version”)
- when deployment failed (one or more service deployments) or
- when a Quality Gate did not pass (QGs can be configured as “allowed to fail”)
- Queueing - orchestration of parallel running pipelines
- at the time of developing the solution GitLab did not provide the feature (in contrast Jenkins provides this out-of-the-box), therefor we had to implement it
- Notification (Rocket.Chat) of ‘Start’ and ‘Finish’ (with details like ‘Success’, ‘Failure’ and ‘Cause’)
Tech Environment:
- AWS Cloud
- App and backend services run as Docker containers
- Data is provided via AWS S3 Service (S3 Object Store)
- S3-buckets separated by purpose (preview, live), with access only from specified environments, and in different accounts (prod, non-prod)
- Configuration of Data-Version via AWS SSM Parameters
- Kuberentes on AWS - EKS
- Docker on AWS - ECR
- Helm (Helmchart, Helmfile)
- GitOps - Continuous Deployment
- GitLab-CI - Continuous Integration
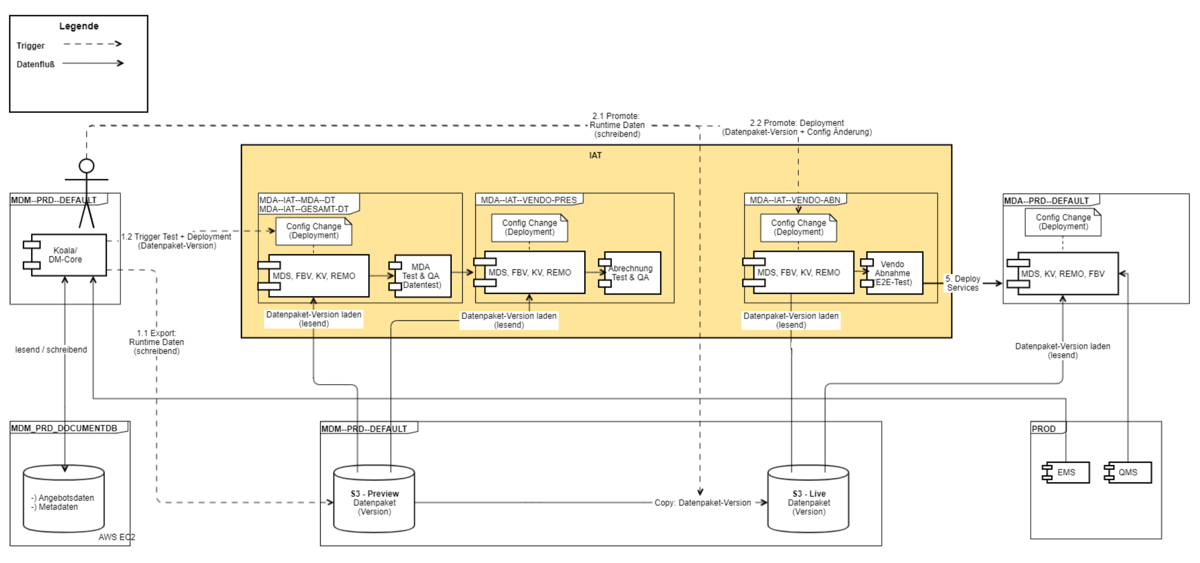
Architecture Overview
Deployment Schema and Runtime View (PRODUCTION):
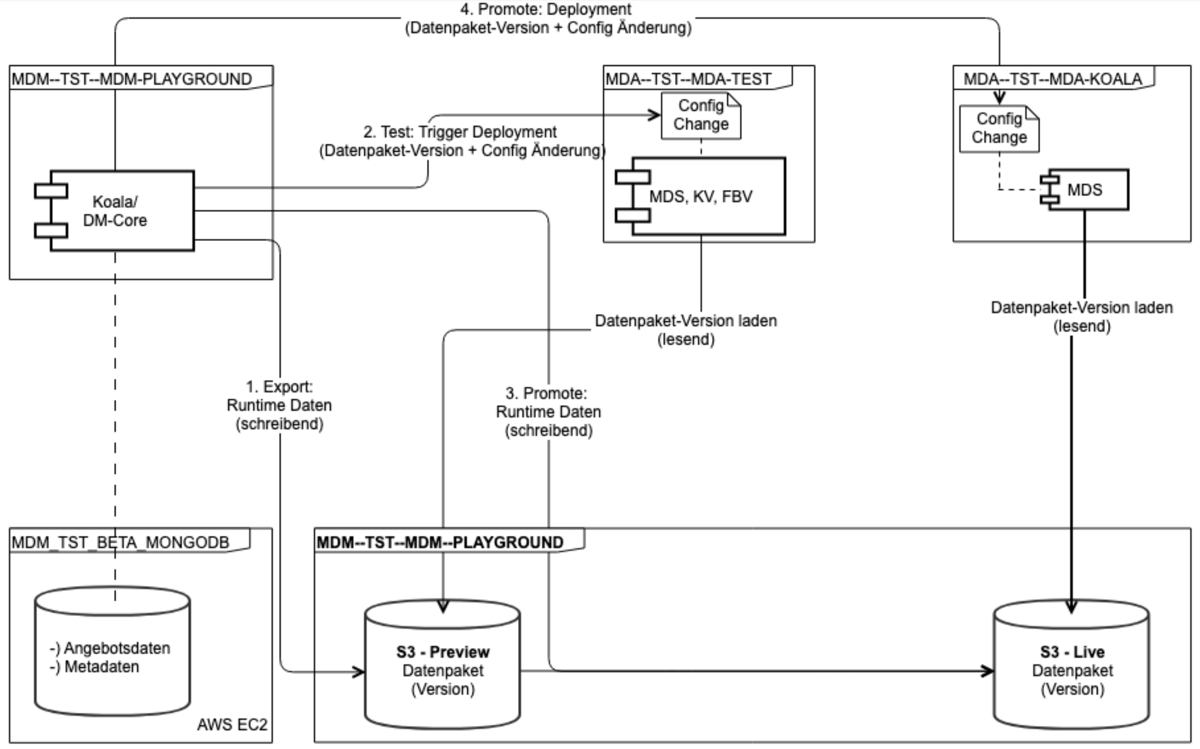
Deployment Schema and Runtime View (PLAYGROUND):
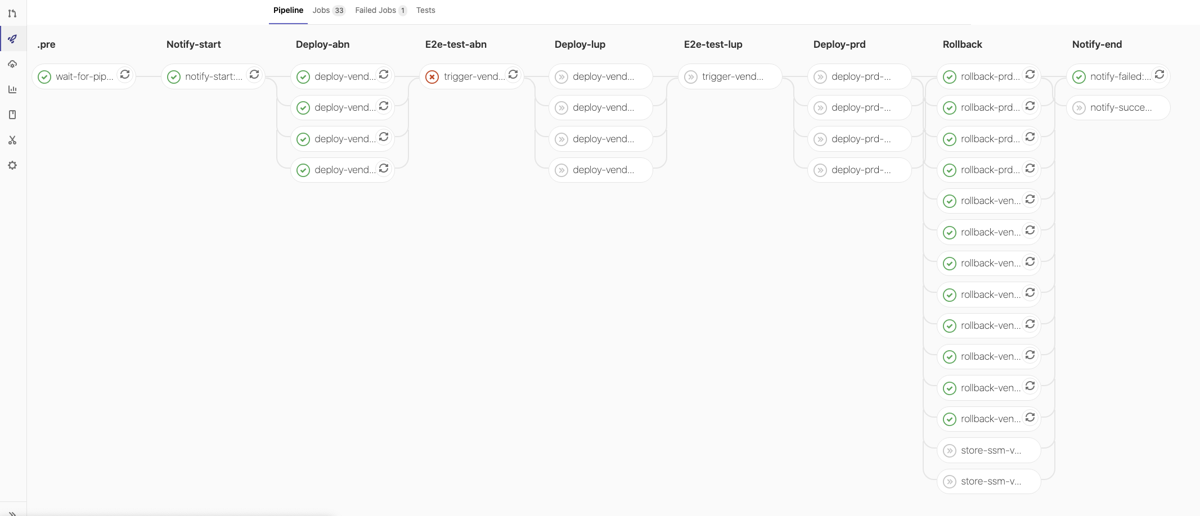
Examples of Data Pipelines in GitLab-CI
Int-Env - Successful run: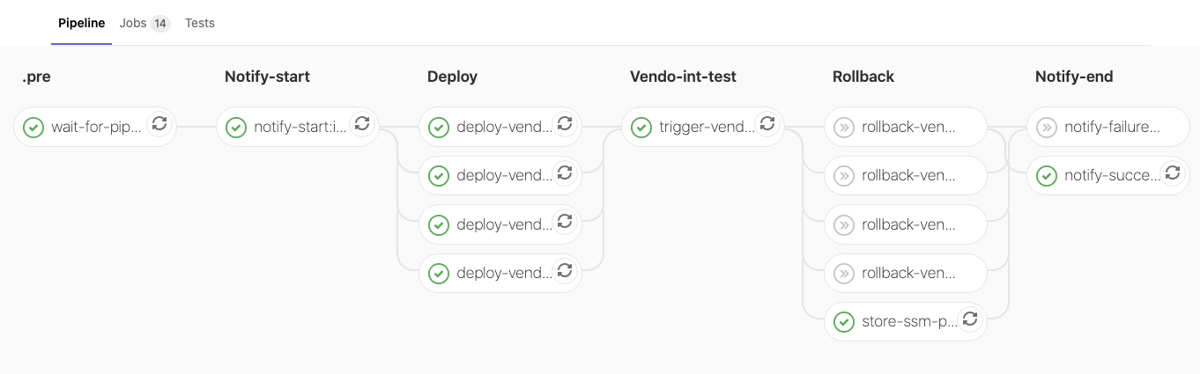
QG ‘Int-Test’ failed and Rollback: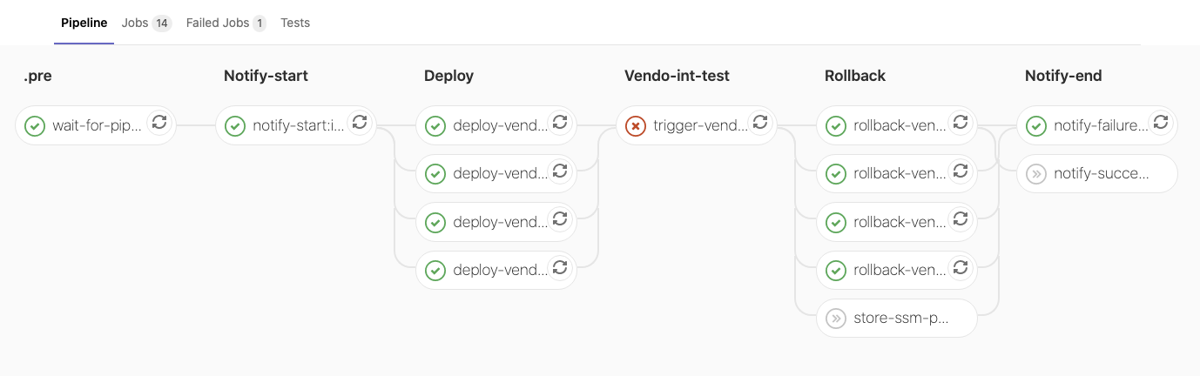
Deployment failed and Rollback failed: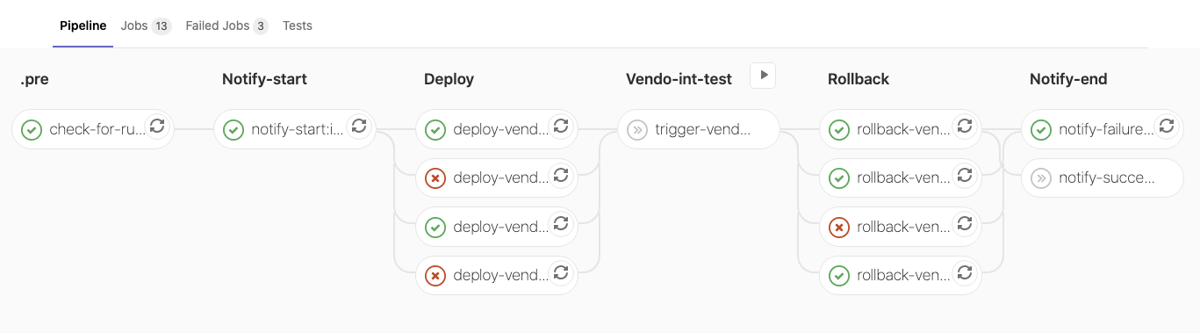
PreProd-Env Successful run: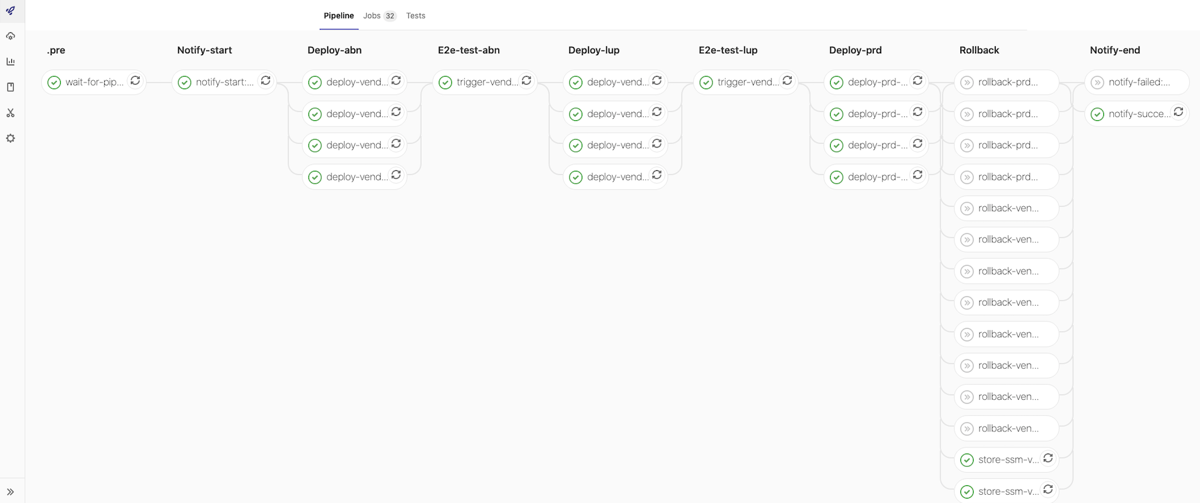
QG ‘LuP-Test’ allowed to fail, successful run: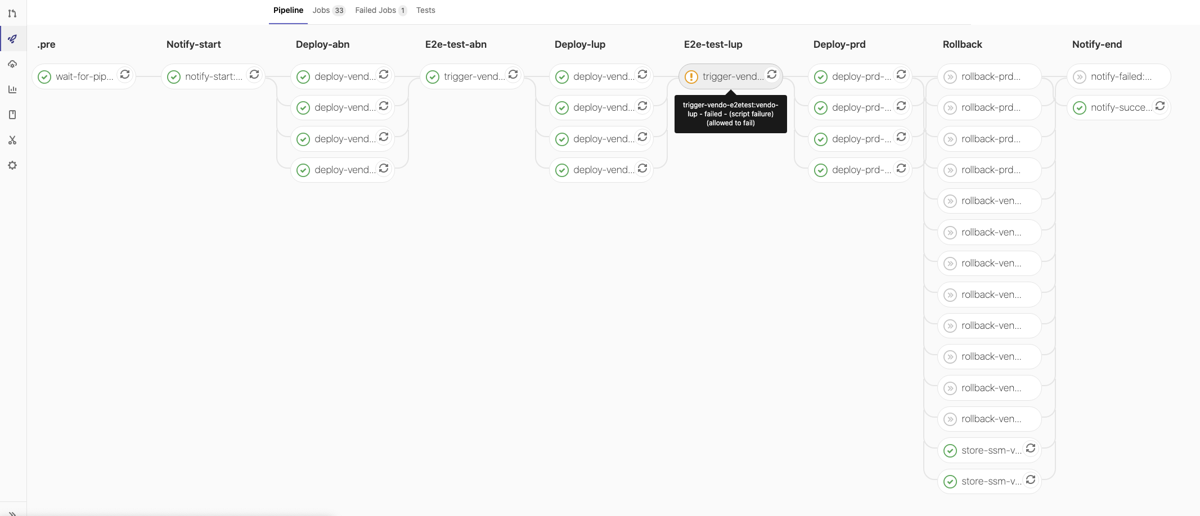
QG ‘ABN-Test’ failed, Rollback: